Instalar y configurar Clúster Linux GFS2 En Rhel 8/9, Rocky Linux, Alma Linux
Nota: Para Instalar y configurar un clúster de rhel 8 usando un fence de iscsi se debe seguir la siguiente guía previa https://blog.kalishell.com.co/linux/como-configurar-un-servidor-iscsi-target-y-iscsi-cliente-initiator-en-rhel-8/
Antes de realizar la configuración del clúster debemos conocer algunos conceptos técnicos
Fence: fence" se refiere a un dispositivo o método utilizado para aislar nodos defectuosos o inaccesibles del clúster. La palabra "fence" es una abreviatura de "stonith" que significa "Shoot The Other Node In The Head" El término "stonith" es más descriptivo de la función: garantizar la disponibilidad del clúster eliminando nodos problemáticos. En un entorno de clúster, la función de "fencing" es crucial para mantener la integridad del clúster y evitar problemas como la partición del clúster, donde los nodos pueden perder la comunicación entre sí. En tales situaciones, un nodo que se considera inalcanzable o defectuoso se "apaga" o se aísla del clúster para evitar situaciones impredecibles o corrupción de datos.
Fence de Red (Network Fencing):
- Este método implica desconectar físicamente el nodo problemático de la red. Puede hacerse apagando un interruptor de red, desconectando un cable de red, o utilizando hardware especializado.
Fence de Alimentación (Power Fencing):
- En este enfoque, se corta la alimentación eléctrica del nodo inalcanzable utilizando dispositivos de administración de energía remotos (PDU - Unidad de Distribución de Energía) o interruptores de alimentación.
Fence de Almacenamiento (Storage Fencing):
- Este método implica desmontar o cortar el acceso a los recursos de almacenamiento compartido que están siendo utilizados por el nodo problemático.
Fence de IPMI (Intelligent Platform Management Interface):
- Utiliza las funciones de administración remota de hardware proporcionadas por el estándar IPMI para apagar o reiniciar un nodo de forma remota.
Quorum: "quorum" se refiere a la mayoría de votos o nodos necesarios para tomar decisiones en un clúster. En sistemas de clúster, especialmente en entornos de alta disponibilidad como Red Hat Enterprise Linux (RHEL) con Pacemaker, el quorum es esencial para evitar problemas de partición y tomar decisiones coherentes sobre el estado del clúster.
El quorum se utiliza para garantizar que solo un conjunto específico de nodos en el clúster (mayoría) tenga la autoridad para continuar operando y tomar decisiones. Esto ayuda a evitar situaciones donde el clúster podría dividirse en subconjuntos que no pueden comunicarse entre sí, lo que podría llevar a problemas de consistencia y operación no segura.
En un clúster, el quorum se puede implementar de varias maneras, y las implementaciones pueden variar según el software de clúster utilizado. Algunas estrategias comunes de quorum incluyen:
Quorum de Nodo (Node Quorum):
- Se basa en la cantidad de nodos en el clúster. Si la mitad o más de los nodos están operativos, el clúster tiene quorum. Esto ayuda a evitar situaciones de partición.
Quorum de Voto (Votes Quorum):
- Cada nodo en el clúster tiene un número específico de votos. La mayoría de votos (por ejemplo, más del 50%) se necesita para tener quorum.
1 .Instalar Paquetes Necesarios para la instalación del cluster:
- para instalar los paquetes en rhel 8/9 debemos habilitar los siguientes repositorios.
subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms subscription-manager repos --enable=rhel-8-for-x86_64-resilientstorage-rpms
- Para instalar los paquetes en Rocky Linux, Alma Linux debemos habilitar los siguientes repositorios
dnf config-manager --set-enabled ha dnf config-manager --set-enabled resilient-storage dnf config-manager --set-enabled resilientstorage
2. Una vez habilitados los repositorios instalamos los paquetes de las siguientes de las siguiente manera.
yum install pcs pacemaker fence-agents-all yum install lvm2-lockd gfs2-utils dlm yum install pcp-zeroconf
3. Habilitar los servicios de clúster en firewall de los nodos que van hacer parte del cluster
firewall-cmd --permanent --add-service=high-availability firewall-cmd --reload
4. al instalar el paquete pacemaker se crea un usuario llamado hacluster. procederemos a cambiar la contraseña del usuario hacluster en ambos nodos la contraseña debe ser igual para todos los nodos del clúster
passwd hacluster
5. Habilitaremos el servicio de pacemaker en ambos nodos de la siguiente forma
systemctl enable --now pcsd.service
6. Ahora vamos autenticar los nodos que pertenecerán al clúster de la siguiente manera
- Nota: este comando solo lo ejecutamos en un solo nodo
pcs host auth cliente01.kalishell.local cliente02.kalishell.local -u hacluster
Cuando ejecutemos este comando nos pedirá la contraseña del usuario hacluster que previamente en el paso 4 se la cambiamos
pcs host auth cliente01.kalishell.local cliente02.kalishell.local -u hacluster
Password:
cliente01.kalishell.local: Authorized
cliente02.kalishell.local: Authorized
7 . Crearemos el clúster en este caso le daré un nombre que Sera ClusterGFS2 para eso ejecutaremos el siguiente comando
pcs cluster setup ClusterGFS2 --start cliente01.kalishell.local cliente02.kalishell.local
8 . Ahora procederemos a habilitar el clúster. Esto lo haremos con el siguiente comando.
pcs cluster enable --all pcs cluster status
Ahora tenemos Creado el clúster. Pero debemos crear también los recursos stonith, fence, Quorum
10. crearemos el stonith usando iscsi para eso debemos identificar el disco usado con iscsi. Esto lo hacemos de la siguiente manera
ll /dev/disk/by-id/ | grep sdb
lrwxrwxrwx. 1 root root 9 Jan 9 22:06 scsi-1LIO-ORG_sdb1-disk:6a49c346-f348-46bc-9917-72a57a6fc95c -> ../../sdb
lrwxrwxrwx. 1 root root 9 Jan 9 22:06 scsi-360014056a49c346f34846bc991772a57 -> ../../sdb
lrwxrwxrwx. 1 root root 9 Jan 9 22:06 scsi-SLIO-ORG_sdb1-disk_6a49c346-f348-46bc-9917-72a57a6fc95c -> ../../sdb
lrwxrwxrwx. 1 root root 9 Jan 9 22:06 wwn-0x60014056a49c346f34846bc991772a57 -> ../../sdb
- Identificado el disco procederemos a configurarlo de la siguiente manera. El nombre de stonith será fence_scsi
pcs stonith create scsi shooter fence_scsi pcmk_host_list="cliente01.kalishell.local cliente02.kalishell.local" devices=/dev/disk/by-id/wwn-0x60014056a49c346f34846bc991772a57 meta provides=unfencing
11 . Habilitaremos un características de lvm en ambos nodos del clúster la característica es use_lvmlockd el valor será a 1
- /etc/lvm/lvm.conf
- use_lvmlockd = 1
Nota: Por defecto, el valor de no-quorum-policy está configurado para stop, lo que indica que una vez que se pierde el quórum, todos los recursos en la partición restante se detendrán inmediatamente. Por lo general, este valor predeterminado es la opción más segura y óptima, pero a diferencia de la mayoría de los recursos, GFS2 requiere quórum para funcionar. Cuando se pierde quórum, tanto las aplicaciones que utilizan los soportes GFS2 como el montaje GFS2 en sí no se pueden detener correctamente. Cualquier intento de detener estos recursos sin quórum fallará, lo que finalmente resultará en que todo el grupo esté cercado cada vez que se pierda quórum.
Para abordar esta situación, establezca no-quorum-policy a freeze cuando GFS2 está en uso. Esto significa que cuando se pierde el quórum, la partición restante no hará nada hasta que se recupere el quórum.
12 . Habilitamos el quorum
pcs property set no-quorum-policy=freeze
13. Configurar un recurso dlm . Esta es una dependencia requerida para configurar un sistema de archivos GFS2 en un clúster. Este ejemplo crea el recursodlm como parte de un grupo de recursos nombrado locking.
pcs resource create dlm --group locking ocf:pacemaker:controld op monitor interval=30s on-fail=fence
14. Clonar el grupo locking de recursos para que el grupo de recursos pueda estar activo en ambos nodos del clúster.
pcs resource clone locking interleave=true
15. Configurar un recursolvmlockd como parte de la locking grupo de recursos
pcs resource create lvmlockd --group locking ocf:heartbeat:lvmlockd op monitor interval=30s on-fail=fence
16. Hacemos un check del estado del clúster en el siguiente comando
pcs status --full
pcs status --full
Cluster name: ClusterGFS2
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: cliente01.kalishell.local (1) (version 2.1.6-8.el8-6fdc9deea29) - partition with quorum
* Last updated: Wed Jan 10 01:17:16 2024 on cliente02.kalishell.local
* Last change: Wed Jan 10 01:11:41 2024 by root via cibadmin on cliente01.kalishell.local
* 2 nodes configured
* 5 resource instances configured
Node List:
* Node cliente01.kalishell.local (1): online, feature set 3.17.4
* Node cliente02.kalishell.local (2): online, feature set 3.17.4
Full List of Resources:
* scsi-shooter (stonith:fence_scsi): Started cliente01.kalishell.local
* Clone Set: locking-clone [locking]:
* Resource Group: locking:0:
* dlm (ocf::pacemaker:controld): Started cliente01.kalishell.local
* lvmlockd (ocf::heartbeat:lvmlockd): Started cliente01.kalishell.local
* Resource Group: locking:1:
* dlm (ocf::pacemaker:controld): Started cliente02.kalishell.local
* lvmlockd (ocf::heartbeat:lvmlockd): Started cliente02.kalishell.local
Tickets:
PCSD Status:
cliente01.kalishell.local: Online
cliente02.kalishell.local: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
17 . En un nodo del clúster, cree un grupo de volumen compartido. Un grupo de volúmenes contendrá un sistemas de archivos GFS2
El siguiente comando crea el grupo de volumen compartido shared_vg1 en `/dev/sdb.
[root@cliente01 ~]# vgcreate --shared shared_vg1 /dev/sdb
Physical volume "/dev/sdb" successfully created.
Volume group "shared_vg1" successfully created
VG shared_vg1 starting dlm lockspace
Starting locking. Waiting until locks are ready...
18. En el segundo nodo del clúster ejecute el siguiente comandos
[root@client02 ~]# vgchange --lockstart shared_vg1
VG shared_vg1 starting dlm lockspace
Starting locking. Waiting until locks are ready...
19. En un nodo del clúster, cree los volúmenes lógicos compartidos y formatee los volúmenes con un sistema de archivos GFS2. Se requiere un diario para cada nodo que monta el sistema de archivos. Asegúrese de crear suficientes revistas para cada uno de los nodos de su clúster. El formato del nombre de la tabla de bloqueo es Nombre del clúster:FSName donde ClusterNombre es el nombre del clúster para el que se está creando el sistema de archivos GFS2 y FSName es el nombre del sistema de archivos, que debe ser único para todos lock_dlm sistemas de archivos sobre el clúster.
[root@cliente01 ~]# lvcreate --activate sy -l 100%FREE -n shared_lv1 shared_vg1
Logical volume "shared_lv1" created.
[root@cliente01 ~]# mkfs.gfs2 -j5 -p lock_dlm -t ClusterGFS2:gfs2-opt-app /dev/shared_vg1/shared_lv1
20. Crear un LVM-activate recurso para cada volumen lógico para activar automáticamente ese volumen lógico en todos los nodos.
[root@cliente01 ~]# pcs resource create sharedlv1 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockd
21. Clone el nuevo grupo de recurso
[root@cliente01 ~]# pcs resource clone shared_vg1 interleave=true
22. Configure las restricciones de pedido para garantizar que el locking grupo de recursos que incluye el dlm y lvmlockd los recursos comiencen primero.
[root@cliente01 ~]# pcs constraint order start locking-clone then shared_vg1-clone
23. Configure las restricciones de colocación para garantizar que el vg1 los grupos de recursos comienzan en el mismo nodo que el locking grupo de recursos.
[root@cliente01 ~]# pcs constraint colocation add shared_vg1-clone with locking-clone
24. En ambos nodos del clúster, verifique que los volúmenes lógicos estén activos. Puede haber un retraso de unos segundos.
[root@client02 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
audit rhel -wi-ao---- 1.00g
home rhel -wi-ao---- 2.00g
log rhel -wi-ao---- 4.00g
opt rhel -wi-ao---- 3.00g
root rhel -wi-ao---- <6.84g
swap rhel -wi-ao---- 3.00g
tmp rhel -wi-ao---- 4.00g
usr rhel -wi-ao---- 4.00g
var rhel -wi-ao---- 4.00g
var_tmp rhel -wi-ao---- 4.00g
shared_lv1 shared_vg1 -wi-a----- 31.99g
[root@cliente01 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
audit rhel -wi-ao---- 1.00g
home rhel -wi-ao---- 2.00g
log rhel -wi-ao---- 4.00g
opt rhel -wi-ao---- 3.00g
root rhel -wi-ao---- <6.84g
swap rhel -wi-ao---- 3.00g
tmp rhel -wi-ao---- 4.00g
usr rhel -wi-ao---- 4.00g
var rhel -wi-ao---- 4.00g
var_tmp rhel -wi-ao---- 4.00g
shared_lv1 shared_vg1 -wi-a----- 31.99g
25. Cree un recurso del sistema de archivos para montar automáticamente cada sistema de archivos GFS2 en todos los nodos
Nota: No debe agregar el sistema de archivos al /etc/fstab archivo porque se administrará como un recurso de clúster de Pacemaker.
[root@cliente01 ~]# pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/opt/app" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence
26. Verificar que los sistemas de archivos GFS2 estén montados en ambos nodos del clúster.
[root@client02 ~]# mount | grep gfs2
/dev/mapper/shared_vg1-shared_lv1 on /opt/app type gfs2 (rw,noatime,seclabel)
[root@cliente01 ~]# mount | grep gfs2
/dev/mapper/shared_vg1-shared_lv1 on /opt/app type gfs2 (rw,noatime,seclabel)
Como podemos ver ya tenemos el sistema de archivo gfs2 montado y compartido correctamente
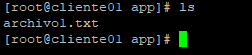
27. Pruebas de lectura escritura sobre el sistema de archivo gfs2. Procederemos a crear un archivo llamado archivo1.txt en el nodo 2 y veremos que se vera reflejado en el nodo1
[root@client02 app]# touch archivo1.txt
[root@cliente01 app]# ls
archivo1.txt
[root@cliente01 app]#